
Relational Databases and SQL
Contents
Relational Databases and SQL¶
In the previous tutorial, we worked with data stored in CSV files. However, CSV files are inconvenient in many real-world scenarios. Data scientists commonly work on a team to analyze a shared dataset. For instance, an financial analyst group might receive new data on an minute basis. Instead of downloading a new CSV file every minute, data scientists prefer to use shared data storage that always reflects the most up-to-date data.
Database systems are software systems specifically designed for large-scale data storage and retrieval. Industry, academic research, and governments all rely on database systems. One common and useful type of database system is an relational database management system (RDBMS). These systems allow data scientists to use a query language called SQL to quickly retrieve and process large amounts of data at once. In this chapter, we introduce the relational database model and SQL.
The Relational Model¶
A database is an organized collection of data. In the past, data was stored in specialized data structures that were designed for specific tasks. For example, airlines might record flight bookings in a different format than a bank managing an account ledger. In 1969, Ted Codd introduced the relational model as a general method of storing data. Data is stored in two-dimensional tables called relations, consisting of individual observations in each row (commonly referred to as tuples). Each tuple is a structured data item that represents the relationship between certain attributes (columns). Each attribute of a relation has a name and data type.
Consider the purchases relation below:
| name | product | retailer | date purchased |
| Samantha | iPod | Best Buy | June 3, 2016 |
| Timothy | Chromebook | Amazon | July 8, 2016 |
| Jason | Surface Pro | Target | October 2, 2016 |
In purchases, each tuple represents the relationship between the name, product, retailer, and date purchased attributes.
A relation’s schema contains its column names, data types, and constraints. For example, the schema of the purchases table states that the columns are name, product, retailer, and date purchased; it also states that each column contains text.
The following prices relation shows the price of certain gadgets at a few retail stores:
| retailer | product | price |
| Best Buy | Galaxy S9 | 719.00 |
| Best Buy | iPod | 200.00 |
| Amazon | iPad | 450.00 |
| Amazon | Battery pack | 24.87 |
| Amazon | Chromebook | 249.99 |
| Target | iPod | 215.00 |
| Target | Surface Pro | 799.00 |
| Target | Google Pixel 2 | 659.00 |
| Walmart | Chromebook | 238.79 |
We can then reference both tables simultaneously to determine how much Samantha, Timothy, and Jason paid for their respective gadgets (assuming prices at each store stay constant over time). Together, the two tables form a relational database, which is a collection of one or more relations. The schema of the entire database is the set of schemas of the individual relations in the database.
Relational Database Management Systems¶
A relational database can be simply described as a set of tables containing rows of individual data entries. A relational database management system (RDBMSs) provides an interface to a relational database. Oracle, MySQL, and PostgreSQL are three of the most commonly used RDBMSs used in practice today.
Relational database management systems give users the ability to add, edit, and remove data from databases. These systems provide several key benefits over using a collection of text files to store data, including:
Reliable data storage: RDBMSs protect against data corruption from system failures or crashes.
Performance: RDBMSs often store data more efficiently than text files and have well-developed algorithms for querying data.
Data management: RDBMSs implement access control, preventing unauthorized users from accessing sensitive datasets.
Data consistency: RDBMSs can impose constraints on the data entered—for example, that a column
GPAonly contains floats between 0.0 and 4.0.
To work with data stored in a RDBMS, we use the SQL programming language.
RDBMS vs. pandas¶
How do RDBMSs and the pandas Python package differ? First, pandas is not concerned about data storage. Although DataFrames can read and write from multiple data formats, pandas does not dictate how the data are actually stored on the underlying computer like a RDBMS does. Second, pandas primarily provides methods for manipulating data while RDBMSs handle both data storage and data manipulation, making them more suitable for larger datasets. A typical rule of thumb is to use a RDBMS for datasets larger than several gigabytes. Finally, pandas requires knowledge of Python in order to use, whereas RDBMSs require knowledge of SQL.
SQL¶
SQL (Structured Query Language) is a programming language that has operations to define, logically organize, manipulate, and perform calculations on data stored in a relational database management system (RDBMS).
SQL is a declarative language. This means that the user only needs to specify what kind of data they want, not how to obtain it. An example is shown below, with an imperative example for comparison:
Declarative: Compute the table with columns “x” and “y” from table “A” where the values in “y” are greater than 100.00.
Imperative: For each record in table “A”, check if the record contains a value of “y” greater than 100. If so, then store the record’s “x” and “y” attributes in a new table. Return the new table.
In this tutorial, we will write SQL queries as Python strings, then use pandas to execute the SQL query and read the result into a pandas DataFrame. As we walk through the basics of SQL syntax, we’ll also occasionally show pandas equivalents for comparison purposes.
Executing SQL Queries through pandas¶
To execute SQL queries from Python, we will connect to a database using the sqlalchemy library. Then we can use the pandas function pd.read_sql to execute SQL queries through this connection.
import pandas as pd
import sqlalchemy
sqlite_uri = "sqlite:///sql_basics.db"
sqlite_engine = sqlalchemy.create_engine(sqlite_uri)
This database contains one relation: prices. To display the relation we run a SQL query. Calling read_sql will execute the SQL query on the RDBMS, then return the results in a pandas DataFrame.
# pd.read_sql takes in a parameter for a SQLite engine, which we create below
sql_expr = """
SELECT *
FROM Prices
"""
prices = pd.read_sql(sql_expr, sqlite_engine)
prices.head()
| retailer | product | price | |
|---|---|---|---|
| 0 | Best Buy | Galaxy S9 | 719.00 |
| 1 | Best Buy | iPod | 200.00 |
| 2 | Amazon | iPad | 450.00 |
| 3 | Amazon | Battery pack | 24.87 |
| 4 | Amazon | Chromebook | 249.99 |
SQL Syntax¶
All SQL queries take the general form below:
SELECT [DISTINCT] <column expression list>
FROM <relation>
[WHERE <predicate>]
[GROUP BY <column list>]
[HAVING <predicate>]
[ORDER BY <column list>]
[LIMIT <number>]
Note
Everything in [square brackets] is optional. A valid SQL query only needs a
SELECTand aFROMstatement.SQL SYNTAX IS GENERALLY WRITTEN IN CAPITAL LETTERS. Although capitalization isn’t required, it is common practice to write SQL syntax in capital letters. It also helps to visually structure your query for others to read.
FROMquery blocks can reference one or more tables, although in this section we will only look at one table at a time for simplicity.
SELECT and FROM¶
The two mandatory statements in a SQL query are:
SELECTindicates the columns that we want to view.FROMindicates the tables from which we are selecting these columns.
To display the entire prices table, we run:
sql_expr = """
SELECT *
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine).head()
| retailer | product | price | |
|---|---|---|---|
| 0 | Best Buy | Galaxy S9 | 719.00 |
| 1 | Best Buy | iPod | 200.00 |
| 2 | Amazon | iPad | 450.00 |
| 3 | Amazon | Battery pack | 24.87 |
| 4 | Amazon | Chromebook | 249.99 |
SELECT * returns every column in the original relation. To display only the retailers that are represented in prices, we add the retailer column to the SELECT statement.
sql_expr = """
SELECT retailer
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine).head()
| retailer | |
|---|---|
| 0 | Best Buy |
| 1 | Best Buy |
| 2 | Amazon |
| 3 | Amazon |
| 4 | Amazon |
If we want a list of unique retailers, we can call the DISTINCT function to omit repeated values.
sql_expr = """
SELECT DISTINCT(retailer)
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine).head()
| retailer | |
|---|---|
| 0 | Best Buy |
| 1 | Amazon |
| 2 | Target |
| 3 | Walmart |
This would be the functional equivalent of the following pandas code:
prices['retailer'].unique()
array(['Best Buy', 'Amazon', 'Target', 'Walmart'], dtype=object)
Each RDBMS comes with its own set of functions that can be applied to attributes in the SELECT list, such as comparison operators, mathematical functions and operators, and string functions and operators. Here we use PostgreSQL, a mature RDBMS that comes with hundreds of such functions, the complete list is available here. Keep in mind that each RDBMS has a different set of functions for use in SELECT.
The following code converts all retailer names to uppercase and halves the product prices.
sql_expr = """
SELECT
UPPER(retailer) AS retailer_caps,
product,
price / 2 AS half_price
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine).head(10)
| retailer_caps | product | half_price | |
|---|---|---|---|
| 0 | BEST BUY | Galaxy S9 | 359.500 |
| 1 | BEST BUY | iPod | 100.000 |
| 2 | AMAZON | iPad | 225.000 |
| 3 | AMAZON | Battery pack | 12.435 |
| 4 | AMAZON | Chromebook | 124.995 |
| 5 | TARGET | iPod | 107.500 |
| 6 | TARGET | Surface Pro | 399.500 |
| 7 | TARGET | Google Pixel 2 | 329.500 |
| 8 | WALMART | Chromebook | 119.395 |
| 9 | BEST BUY | Galaxy S9 | 359.500 |
Note
Notice that we can alias the columns (assign another name) with AS so that the columns appear with this new name in the output table. This does not modify the names of the columns in the source relation.
WHERE¶
The WHERE clause allows us to specify certain constraints for the returned data; these constraints are often referred to as predicates. For example, to retrieve only gadgets that are under $500:
sql_expr = """
SELECT *
FROM prices
WHERE price < 500
"""
pd.read_sql(sql_expr, sqlite_engine).head(10)
| retailer | product | price | |
|---|---|---|---|
| 0 | Best Buy | iPod | 200.00 |
| 1 | Amazon | iPad | 450.00 |
| 2 | Amazon | Battery pack | 24.87 |
| 3 | Amazon | Chromebook | 249.99 |
| 4 | Target | iPod | 215.00 |
| 5 | Walmart | Chromebook | 238.79 |
| 6 | Best Buy | iPod | 200.00 |
| 7 | Amazon | iPad | 450.00 |
| 8 | Amazon | Battery pack | 24.87 |
| 9 | Amazon | Chromebook | 249.99 |
We can also use the operators AND, OR, and NOT to further constrain our SQL query. To find an item on Amazon without a battery pack under $300, we write:
sql_expr = """
SELECT *
FROM prices
WHERE retailer = 'Amazon'
AND NOT product = 'Battery pack'
AND price < 300
"""
pd.read_sql(sql_expr, sqlite_engine)
| retailer | product | price | |
|---|---|---|---|
| 0 | Amazon | Chromebook | 249.99 |
| 1 | Amazon | Chromebook | 249.99 |
| 2 | Amazon | Chromebook | 249.99 |
The equivalent operation in pandas is:
prices[(prices['retailer'] == 'Amazon')
& ~(prices['product'] == 'Battery pack')
& (prices['price'] <= 300)]
| retailer | product | price | |
|---|---|---|---|
| 4 | Amazon | Chromebook | 249.99 |
| 13 | Amazon | Chromebook | 249.99 |
| 22 | Amazon | Chromebook | 249.99 |
Note
There’s a subtle difference that’s worth noting: the index of the Chromebook in the SQL query is 0, whereas the corresponding index in the DataFrame is 4. This is because SQL queries always return a new table with indices counting up from 0, whereas pandas subsets a portion of the DataFrame prices and returns it with the original indices. We can use pd.DataFrame.reset_index to reset the indices in pandas.
Aggregate Functions¶
So far, we’ve only worked with data from the existing rows in the table; that is, all of our returned tables have been some subset of the entries found in the table. But to conduct data analysis, we’ll want to compute aggregate values over our data. In SQL, these are called aggregate functions.
If we want to find the average price of all gadgets in the prices relation:
sql_expr = """
SELECT AVG(price) AS avg_price
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine)
| avg_price | |
|---|---|
| 0 | 395.072222 |
Equivalently, in pandas:
prices['price'].mean()
395.07222222222225
A complete list of PostgreSQL aggregate functions can be found here. Though we’re using PostgreSQL as our primary version of SQL, keep in mind that there are many other variations of SQL (MySQL, SQLite, etc.) that use different function names and have different functions available.
GROUP BY and HAVING¶
With aggregate functions, we can execute more complicated SQL queries. To operate on more granular aggregate data, we can use the following two clauses:
GROUP BYtakes a list of columns and groups the table like the pd.DataFrame.groupby function inpandas.HAVINGis functionally similar toWHERE, but is used exclusively to apply conditions to aggregated data. (Note that in order to useHAVING, it must be preceded by aGROUP BYclause.)
Important: When using GROUP BY, all columns in the SELECT clause must be either listed in the GROUP BY clause or have an aggregate function applied to them.
We can use these statements to find the maximum price at each retailer.
sql_expr = """
SELECT retailer, MAX(price) as max_price
FROM prices
GROUP BY retailer
"""
pd.read_sql(sql_expr, sqlite_engine)
| retailer | max_price | |
|---|---|---|
| 0 | Amazon | 450.00 |
| 1 | Best Buy | 719.00 |
| 2 | Target | 799.00 |
| 3 | Walmart | 238.79 |
Let’s say we have a client with expensive taste and only want to find retailers that sell gadgets over $700. Note that we must use HAVING to define conditions on aggregated columns; we can’t use WHERE to filter an aggregated column. To compute a list of retailers and accompanying prices that satisfy our needs, we run:
sql_expr = """
SELECT retailer, MAX(price) as max_price
FROM prices
GROUP BY retailer
HAVING max_price > 700
"""
pd.read_sql(sql_expr, sqlite_engine)
| retailer | max_price | |
|---|---|---|
| 0 | Best Buy | 719.0 |
| 1 | Target | 799.0 |
For comparison, we recreate the same table in pandas:
max_prices = prices.groupby('retailer').max()
max_prices.loc[max_prices['price'] > 700, ['price']]
| price | |
|---|---|
| retailer | |
| Best Buy | 719.0 |
| Target | 799.0 |
ORDER BY and LIMIT¶
These clauses allow us to control the presentation of the data:
ORDER BYlets us present the data in alphabetical order of column values. By default, ORDER BY uses ascending order (ASC) but we can specify descending order usingDESC.LIMITcontrols how many tuples are displayed.
Let’s display the three cheapest items in our prices table:
sql_expr = """
SELECT *
FROM prices
ORDER BY price ASC
LIMIT 3
"""
pd.read_sql(sql_expr, sqlite_engine)
| retailer | product | price | |
|---|---|---|---|
| 0 | Amazon | Battery pack | 24.87 |
| 1 | Amazon | Battery pack | 24.87 |
| 2 | Amazon | Battery pack | 24.87 |
Note that we didn’t have to include the ASC keyword since ORDER BY returns data in ascending order by default.
For comparison, in pandas:
prices.sort_values('price').head(3)
| retailer | product | price | |
|---|---|---|---|
| 3 | Amazon | Battery pack | 24.87 |
| 21 | Amazon | Battery pack | 24.87 |
| 12 | Amazon | Battery pack | 24.87 |
(Again, we see that the indices are out of order in the pandas DataFrame. As before, pandas returns a view on our DataFrame prices, whereas SQL is displaying a new table each time that we execute a query.)
Conceptual SQL Evaluation¶
Clauses in a SQL query are executed in a specific order. Unfortunately, this order differs from the order that the clauses are written in a SQL query. From first executed to last:
FROM: One or more source tablesWHERE: Apply selection qualifications (eliminate rows)GROUP BY: Form groups and aggregateHAVING: Eliminate groupsSELECT: Select columns
Note on WHERE vs. HAVING: Since the WHERE clause is processed before applying GROUP BY, the WHERE clause cannot make use of aggregated values. To define predicates based on aggregated values, we must use the HAVING clause.
SQL Joins¶
In pandas we used the pd.merge method to join two tables using matching values in their columns. For example:
pd.merge(table1, table2, on='common_column')
In this section, we introduce SQL joins. SQL joins are used to combine multiple tables in a relational database.
Suppose we are cat store owners with a database for the cats we have in our store. We have two different tables: names and colors. The names table contains the columns cat_id, a unique number assigned to each cat, and name, the name for the cat. The colors table contains the columns cat_id and color, the color of each cat.
Note
Note that there are some missing rows from both tables - a row with cat_id 3 is missing from the names table, and a row with cat_id 4 is missing from the colors table.
| cat_id | name |
|---|---|
| 0 | Apricot |
| 1 | Boots |
| 2 | Cally |
| 4 | Eugene |
| cat_id | color |
|---|---|
| 0 | orange |
| 1 | black |
| 2 | calico |
| 3 | white |
To compute the color of the cat named Apricot, we have to use information in both tables. We can join the tables on the cat_id column, creating a new table with both name and color.
Joins¶
A join combines tables by matching values in their columns.
There are four main types of joins: inner joins, outer joins, left joins, and right joins. Although all four combine tables, each one treats non-matching values differently.
Inner Join¶
Definition: In an inner join, the final table only contains rows that have matching columns in both tables.
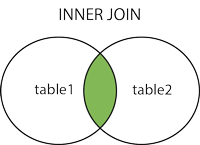
Example: We would like to join the names and colors tables together to match each cat with its color. Since both tables contain a cat_id column that is the unique identifier for a cat, we can use an inner join on the cat_id column.
SQL: To write an inner join in SQL we modify our FROM clause to use the following syntax:
SELECT ...
FROM <TABLE_1>
INNER JOIN <TABLE_2>
ON <...>
For example:
SELECT *
FROM names AS N
INNER JOIN colors AS C
ON N.cat_id = C.cat_id;
| cat_id | name | cat_id | color | |
|---|---|---|---|---|
| 0 | 0 | Apricot | 0 | orange |
| 1 | 1 | Boots | 1 | black |
| 2 | 2 | Cally | 2 | calico |
You may verify that each cat name is matched with its color. Notice that the cats with cat_id 3 and 4 are not present in our resulting table because the colors table doesn’t have a row with cat_id 4 and the names table doesn’t have a row with cat_id 3. In an inner join, if a row doesn’t have a matching value in the other table, the row is not included in the final result.
Assuming we have a DataFrame called names and a DataFrame called colors, we can conduct an inner join in pandas by writing:
pd.merge(names, colors, how='inner', on='cat_id')
Full/Outer Join¶
Definition: In a full join (sometimes called an outer join), all records from both tables are included in the joined table. If a row doesn’t have a match in the other table, the missing values are filled in with NULL.
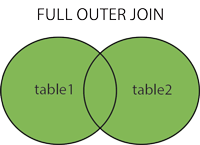
Example: As before, we join the names and colors tables together to match each cat with its color. This time, we want to keep all rows in either table even if there isn’t a match.
SQL: To write an outer join in SQL we modify our FROM clause to use the following syntax:
SELECT ...
FROM <TABLE_1>
FULL JOIN <TABLE_2>
ON <...>
For example:
SELECT name, color
FROM names N
FULL JOIN colors C
ON N.cat_id = C.cat_id;
cat_id |
name |
color |
|---|---|---|
0 |
Apricot |
orange |
1 |
Boots |
black |
2 |
Cally |
calico |
3 |
NULL |
white |
4 |
Eugene |
NULL |
Note
Notice that the final output contains the entries with cat_id 3 and 4. If a row does not have a match, it is still included in the final output and any missing values are filled in with NULL.
In pandas:
pd.merge(names, colors, how='outer', on='cat_id')
Left Join¶
Definition: In a left join, all records from the left table are included in the joined table. If a row doesn’t have a match in the right table, the missing values are filled in with NULL.
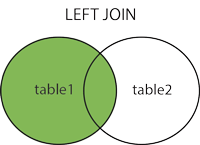
Example: As before, we join the names and colors tables together to match each cat with its color. This time, we want to keep all the cat names even if a cat doesn’t have a matching color.
SQL: To write an left join in SQL we modify our FROM clause to use the following syntax:
SELECT ...
FROM <TABLE_1>
LEFT JOIN <TABLE_2>
ON <...>
For example:
SELECT name, color
FROM names N
LEFT JOIN colors C
ON N.cat_id = C.cat_id;
cat_id |
name |
color |
|---|---|---|
0 |
Apricot |
orange |
1 |
Boots |
black |
2 |
Cally |
calico |
4 |
Eugene |
NULL |
Note
Notice that the final output includes all four cat names. Three of the cat_ids in the names relation had matching cat_ids in the colors table and one did not (Eugene). The cat name that did not have a matching color has NULL as its color.
In pandas:
pd.merge(names, colors, how='left', on='cat_id')
Right Join¶
Definition: In a right join, all records from the right table are included in the joined table. If a row doesn’t have a match in the left table, the missing values are filled in with NULL.
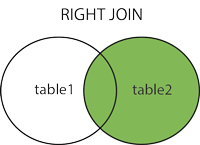
Example: As before, we join the names and colors tables together to match each cat with its color. This time, we want to keep all the cat color even if a cat doesn’t have a matching name.
SQL: To write a right join in SQL we modify our FROM clause to use the following syntax:
SELECT ...
FROM <TABLE_1>
RIGHT JOIN <TABLE_2>
ON <...>
For example:
SELECT name, color
FROM names N
RIGHT JOIN colors C
ON N.cat_id = C.cat_id;
cat_id |
name |
color |
|---|---|---|
0 |
Apricot |
orange |
1 |
Boots |
black |
2 |
Cally |
calico |
3 |
NULL |
white |
This time, observe that the final output includes all four cat colors. Three of the cat_ids in the colors relation had matching cat_ids in the names table and one did not (white). The cat color that did not have a matching name has NULL as its name.
You may also notice that a right join produces the same result a left join with the table order swapped. That is, names left joined with colors is the same as colors right joined with names. Because of this, some SQL engines (such as SQLite) do not support right joins.
In pandas:
pd.merge(names, colors, how='right', on='cat_id')
Implicit Inner Joins¶
There are typically multiple ways to accomplish the same task in SQL just as there are multiple ways to accomplish the same task in Python. We point out one other method for writing an inner join that appears in practice called an implicit join. Recall that we previously wrote the following to conduct an inner join:
SELECT *
FROM names AS N
INNER JOIN colors AS C
ON N.cat_id = C.cat_id;
An implicit inner join has a slightly different syntax. Notice in particular that the FROM clause uses a comma to select from two tables and that the query includes a WHERE clause to specify the join condition.
SELECT *
FROM names AS N, colors AS C
WHERE N.cat_id = C.cat_id;
When multiple tables are specified in the FROM clause, SQL creates a table containing every combination of rows from each table. For example:
sql_expr = """
SELECT *
FROM names N, colors C
"""
pd.read_sql(sql_expr, sqlite_engine)
| cat_id | name | cat_id | color | |
|---|---|---|---|---|
| 0 | 0 | Apricot | 0 | orange |
| 1 | 0 | Apricot | 1 | black |
| 2 | 0 | Apricot | 2 | calico |
| 3 | 0 | Apricot | 3 | white |
| 4 | 1 | Boots | 0 | orange |
| 5 | 1 | Boots | 1 | black |
| 6 | 1 | Boots | 2 | calico |
| 7 | 1 | Boots | 3 | white |
| 8 | 2 | Cally | 0 | orange |
| 9 | 2 | Cally | 1 | black |
| 10 | 2 | Cally | 2 | calico |
| 11 | 2 | Cally | 3 | white |
| 12 | 4 | Eugene | 0 | orange |
| 13 | 4 | Eugene | 1 | black |
| 14 | 4 | Eugene | 2 | calico |
| 15 | 4 | Eugene | 3 | white |
This operation is often called a Cartesian product: each row in the first table is paired with every row in the second table. Notice that many rows contain cat colors that are not matched properly with their names. The additional WHERE clause in the implicit join filters out rows that do not have matching cat_id values.
SELECT *
FROM names AS N, colors AS C
WHERE N.cat_id = C.cat_id;
| cat_id | name | cat_id | color | |
|---|---|---|---|---|
| 0 | 0 | Apricot | 0 | orange |
| 1 | 1 | Boots | 1 | black |
| 2 | 2 | Cally | 2 | calico |
Joining Multiple Tables¶
To join multiple tables, extend the FROM clause with additional JOIN operators. For example, the following table ages includes data about each cat’s age.
cat_id |
age |
|---|---|
0 |
4 |
1 |
3 |
2 |
9 |
4 |
20 |
To conduct an inner join on the names, colors, and ages table, we write:
# Joining three tables
sql_expr = """
SELECT name, color, age
FROM names n
INNER JOIN colors c ON n.cat_id = c.cat_id
INNER JOIN ages a ON n.cat_id = a.cat_id;
"""
pd.read_sql(sql_expr, sqlite_engine)
| name | color | age | |
|---|---|---|---|
| 0 | Apricot | orange | 4 |
| 1 | Boots | black | 3 |
| 2 | Cally | calico | 9 |
Summary¶
We have introduced SQL syntax and the most important SQL statements needed to conduct data analysis using a relational database management system.
We have covered the four main types of SQL joins: inner, full, left, and right joins. We use all four joins to combine information in separate relations, and each join differs only in how it handles non-matching rows in the input tables.